俹俤俼
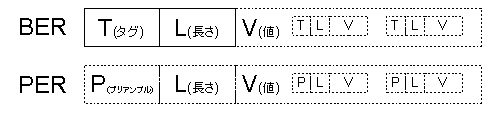
俹俤俼偼 乽壜擻側尷傝扨弮側晞崋壔婯懃傪巊偭偰嵟傕娙寜側晞崋傪摼傞乿傕偺偱偡丅
俛俤俼偺僞僌丒挿偝丒抣偺俿俴倁俁崁慻傒偺戙傢傝偵丄
俹俤俼偼僾儕傾儞僽儖乮暋悢枖偼徣棯偝傟傞応崌偁傝乯丄
挿偝乮徣棯偝傟傞応崌偁傝乯丄抣乮徣棯偝傟傞応崌偁傝乯偺俹俴倁偐傜側傝傑偡丅
僆僋僥僢僩楍偱偼側偔尨懃價僢僩楍偱偡丅 奺梫慺偼師偺庬椶偑偁傝傑偡丅
- 旕惍楍價僢僩僼傿乕儖僪(bit-field)丅
僆僋僥僢僩惍楍偟傑偣傫丅
- 惍楍價僢僩僼傿乕儖僪(octet-aligned bit-field)丅
壓婰偺惍楍宍幃偺応崌偵僆僋僥僢僩惍楍偟傑偡丅
- 僼傿乕儖僪儕僗僩(field-list)丅
旕惍楍價僢僩僼傿乕儖僪傗惍楍價僢僩僼傿乕儖僪傪娷傒傑偡丅
俛俤俼偱偼屄暿儊僢僙乕僕偺俙俽俶丏侾巇條傪抦傜側偔偰傕僞僌偲挿偝傪巊偭偰偁傞掱搙偺暅崋偑壜擻偱偡偑丄
俹俤俼偼挿偝傗抣偺僼傿乕儖僪偑僆僾僔儑儞乮昁梫側応崌偵偺傒巜掕乯偱丄
俙俽俶丏侾巇條偱巜掕偝傟偨奺庬惂尷偵埶懚偟偰晞崋壔偡傞偨傔丄
晞崋壔偲暅崋壔偵偼俙俽俶丏侾巇條偺嶲徠偑昁梫偱偡丅
俛俤俼偱偼丄僞僌偱嬫暿偡傞偙偲偱丄梕堈偵CHOICE傗SET傗SEQUENCE偵梫慺傪捛壛偡傞奼挘偑壜擻偱偟偨偑丄
俹俤俼偼僞僌偑側偄偺偱奼挘惈偼帠慜偵寁夋偟偰偍偔昁梫偑偁傝傑偡丅
奼挘偑巜掕偝傟偰偄傞応崌丄僾儕傾儞僽儖偵奼挘偺桳柍傪帵偡價僢僩偑愝掕偝傟傑偡丅
挿偝偼俙俽俶丏侾巇條偺SIZE惂栺偱屌掕挿偵側偭偰偄偄傞応崌丄堦晹椺奜傪彍偒丄晞崋壔偝傟傑偣傫丅
SEQUENCE傗SET偺抣偺晞崋壔偼丄僆僾僔儑儞梫慺(OPTIONAL傗DEFAULT)偺懚嵼傗旕懚嵼傪帵偡僾儕傾儞僽儖偱巒傑傝傑偡丅
CHOICE偼慖戰巿傪帵偡僀儞僨僢僋僗偐傜巒傑傝傑偡丅
堦斒偵丄俹俤俼偱晞崋壔偼弶婜張棟偑戝偒偄偑僄儞僐乕僪偲僨僐乕僪偼惷揑偱俛俤俼傛傝憗偔丄
俛俤俼傛傝僒僀僘偑彫偝偄偺偱僱僢僩儚乕僋揮憲偑憗偔側傝傑偡丅
1. 晞崋壔偺係偮偺宍幃
俹俤俼偼俀偮宍幃偑偁傝傑偡丗
婎杮宍幃(BASIC-PER)偲惓婯壔宍幃(CANONICAL-PER)偱偡丅
偦偟偰偦傟偧傟惍楍(ALIGNED)偲旕惍楍(UNALIGNED)偑偁傝傑偡丅
惓婯壔宍幃偼婎杮宍幃偵惂尷傪壛偊偨傕偺偱偡丅
偙偺宍幃偼儕儗乕僔僗僥儉傗僨傿僕僞儖彁柤偵揔梡偝傟傑偡丅
婎杮宍幃偱丄抣偼偄偔偮傕偺晞崋壔宍幃傪傕偮偐傕偟傟傑偣傫丅
懠曽丄専嵏偼尷掕偝傟傞偺偱丄婎杮宍幃僐乕僟偼惓婯壔僐乕僟傛傝懍偄偱偟傚偆丅
惍楍宍幃偼僆僋僥僢僩嫬奅偵偦傠偊傞偨傔偵昁梫側傜丄侽偺價僢僩偑憓擖偝傟傑偡丅
旕惍楍宍幃偱僆僋僥僢僩嫬奅偼側偔丄偡傋偰偺價僢僩偑巊傢傟傑偡丅
旕惍楍宍幃偼僐儞僷僋僩偱偡偑丄晞崋壔偲暅崋壔偵傛傝帪娫偑偐偐傞張棟傪昁梫偲偟傑偡丅
惍楍偲旕惍楍偼屳姺惈偑柍偔丄惍楍宍幃僨僐乕僟偼旕惍楍宍幃傪僨僐乕僪偱偒傑偣傫丅
2. 惍悢偺晞崋壔
2.1. 桳尷斖埻偺惍悢
晞崋壔偡傞惍悢傪n偲偟傑偡丅
惍悢偺斖埻偵惂尷偑偁傞応崌丄偮傑傝嵟彫抣MIN偲嵟戝抣MAX偑寛傑偭偰偄傞応崌丄抣(n-MIN)傪晞崋壔偟傑偡丅
摿偵MIN=MAX偺応崌偼丄抣偑柧傜偐側偺偱晞崋壔偟傑偣傫乮亖徣棯乯丅
側偍丄埲壓偺俀恑宍幃偼丄戞i價僢僩偑2^i傪帵偡堦斒揑側晞崋側偟俀恑宍幃偱偡丅
- 旕惍楍宍幃偺応崌丗
(n-MIN)傪昁梫嵟彫尷偺價僢僩悢乮=log2(MAX-MIN+1)丄彫悢揰埲壓愗忋偘乯偱丄
俀恑朄宍幃偱丄旕惍楍價僢僩僼傿乕儖僪 偵晞崋壔偟傑偡丅
- 惍楍宍幃偺応崌丗斖埻range = MAX-MIN+1偵傛偭偰晞崋壔偑曄傢傝傑偡丅
- range亝255丗
(n-MIN)傪昁梫嵟彫尷偺價僢僩悢乮=log2(range)丄彫悢揰埲壓愗忋偘乯偱丄
俀恑朄宍幃偱丄旕惍楍價僢僩僼傿乕儖僪偵晞崋壔偟傑偡丅僆僋僥僢僩惍楍傪偟傑偣傫丅
- range=256丗
(n-MIN)傪侾僆僋僥僢僩偺丄俀恑朄偺宍幃偱丄惍楍價僢僩僼傿乕儖僪偵晞崋壔偟傑偡丅
僆僋僥僢僩惍楍傪偟傑偡丅
- 257亝range亝65536:
(n-MIN)傪俀僆僋僥僢僩偺丄俀恑朄偺宍幃偱丄惍楍價僢僩僼傿乕儖僪偵晞崋壔偟傑偡丅
僆僋僥僢僩惍楍傪偟傑偡丅
- range亞65537:
壜曄挿埖偄偵側傝傑偡丅
(n-MIN)偺晞崋壔偵昁梫嵟彫側僆僋僥僢僩悢俴乮=log256(n-MIN)丄彫悢揰埲壓愗忋偘乯傪晞崋壔偟丄
偙偺屻偵俴僆僋僥僢僩偺丄俀恑朄偺宍幃偱晞崋壔偟偨惍楍價僢僩僼傿乕儖僪偑懕偒傑偡丅
俴偺僼僅乕儅僢僩偼屻婰偺捠傝偱偡丅
2.2. 捠忢彫偝偄旕晧惍悢
SEQUENCE傗SET偺奼挘價僢僩儅僢僾偺戝偒偝傗CHOICE偺僀儞僨僢僋僗偼惍悢偱丄
堦斒偵彫偝偄偑惂尷偑側偄帠傕懡偄偺偱丄乽捠忢彫偝偄旕晧惍悢宍幃乿偑巊傢傟傑偡丅
晞崋壔偡傞惍悢傪n偲偟傑偡丅
- a) n亝63:
1價僢僩抣偺侽傪旕惍楍價僢僩僼傿乕儖僪偵晞崋壔偟丄
懕偗偰俇價僢僩偱晞崋側偟俀恑宍幃偱値傪旕惍楍價僢僩僼傿乕儖僪偵晞崋壔偟傑偡丅
- b) n亞64:
1價僢僩抣偺1傪旕惍楍價僢僩僼傿乕儖僪偵晞崋壔偟丄
懕偗偰値傪壓婰偺晹暘惂尷惍悢乮MIN=0偲偡傞)偱晞崋壔偟傑偡丅
2.3. 晹暘惂尷惍悢
惍悢値偺壓尷MIN偼桳尷偱偁傞偑忋尷偑+∞偺応崌偺晞崋壔偱偡丅
壜曄挿埖偄偵側傝傑偡丅
(n-MIN)偺晞崋壔偵昁梫嵟彫側僆僋僥僢僩悢俴乮=log256(n-MIN)丄彫悢揰埲壓愗忋偘乯傪晞崋壔偟丄
偙偺屻偵俴僆僋僥僢僩偺晞崋側偟俀恑朄偺宍幃偱晞崋壔偟偨僼傿乕儖僪偑懕偒傑偡丅
旕惍楍宍幃偱偼僼傿乕儖僪偼僆僋僥僢僩惍楍傪偟側偄旕惍楍價僢僩僼傿乕儖僪偱丄
惍楍宍幃偱偼僼傿乕儖僪偼僆僋僥僢僩惍楍傪偡傞惍楍價僢僩僼傿乕儖僪偵側傝傑偡丅
俴偺僼僅乕儅僢僩偼屻婰偺捠傝偱偡丅
2.4. 惂尷側偟偺惍悢
惍悢偺斖埻偵惂尷偑側偄応崌偼丄晞崋晅偒惍悢偱値傪晞崋壔偟傑偡丅
壜曄挿埖偄偵側傝傑偡丅
晞崋壔偵昁梫嵟彫側僆僋僥僢僩悢俴傪晞崋壔偟丄
偙偺屻偵俴僆僋僥僢僩偺晞崋晅偒俀恑朄偺宍幃乮俀偺曗悢昞尰乯偱晞崋壔偟偨僼傿乕儖僪偑懕偒傑偡丅
旕惍楍宍幃偱偼僼傿乕儖僪偼僆僋僥僢僩惍楍傪偟側偄旕惍楍價僢僩僼傿乕儖僪偱丄
惍楍宍幃偱偼僼傿乕儖僪偼僆僋僥僢僩惍楍傪偡傞惍楍價僢僩僼傿乕儖僪偵側傝傑偡丅
俴偺僼僅乕儅僢僩偼屻婰偺捠傝偱偡丅
2.5. 挿偝俴偺晞崋壔
俛俤俼偱偼挿偝僼傿乕儖僪偼忢偵懚嵼偟丄僆僋僥僢僩扨埵偱偟偨偑丄
俹俤俼偱偼挿偝僼傿乕儖僪偼昁梫側応崌偵偩偗懚嵼偟傑偡丅
俛俤俼偱偼挿偝偼僆僋僥僢僩扨埵偱偟偨偑丄俹俤俼偱偼價僢僩楍偱偼價僢僩扨埵丄
僆僋僥僢僩楍乮OCTET STRING傗僆乕僾儞宆乯偱偼僆僋僥僢僩扨埵丄暥帤楍偼暥帤悢丄
SEQUENCE OF傗SET OF偱偼梫慺悢傪昞偟傑偡丅
俙俽俶丏侾巇條偵傛偭偰丄挿偝len偺壓尷乮侽埲忋乯偲忋尷乮∞偐傕偟傟側偄乯偑懚嵼偟丄
偙傟偵傛偭偰挿偝len偺晞崋壔偼塭嬁傪庴偗傑偡丅
- 挿偝len偺忋尷偑65535埲壓偺摿掕偺屌掕偟偨挿偝偺応崌丄
挿偝len偺晞崋壔傪偟傑偣傫乮亖挿偝俴僼傿乕儖僪偼徣棯乯丅
- SET傗SEQUENCE偺僾儕傾儞僽儖偺價僢僩儅僢僾偺挿偝偺応崌丄
(挿偝-1)傪忋婰偺乽捠忢彫偝偄旕晧惍悢乿偱晞崋壔偟傑偡丅
- 惍楍宍幃偺応崌丗
- len偺忋尷抣偑65535埲壓偺応崌丗乽桳尷斖埻偺惍悢乿偱晞崋壔偟傑偡丅
- len偺忋尷抣偑65536埲忋偐丄忋尷偑∞偺応崌丗
- len亝127偺応崌丗
len傪丄侾僆僋僥僢僩偺俀恑朄偺宍幃偱丄晞崋壔偟傑偡丅
惍楍宍幃偱偼僆僋僥僢僩惍楍傪偟傑偡丅
僆僋僥僢僩偺嵟忋埵價僢僩偼忢偵侽偵側傝傑偡丅

- 128亝len亝16383丗
len傪丄俀僆僋僥僢僩偺俀恑朄偺宍幃偱丄惍楍價僢僩僼傿乕儖僪偵晞崋壔偟傑偡丅
惍楍宍幃偱偼僆僋僥僢僩惍楍傪偟傑偡丅
戞侾僆僋僥僢僩偺嵟忋埵價僢僩偼忢偵侾丄師偺價僢僩偼忢偵侽偵側傝傑偡丅
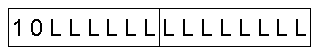
- len亞16384丗
挿偝偺懳徾偲側傞梫慺倁傪暘妱偟偰丄俴倁俴倁偲偄偭偨晞崋壔傪偟傑偡丅
徻嵶偼徣棯偟傑偡丅

- 旕惍楍宍幃偺応崌丗
- len偺忋尷抣偑65535埲壓偺応崌丗
(忋尷=壓尷)偺応崌偼晞崋壔偟傑偣傫丅
偦傟埲奜偺応崌丄(len-壓尷)傪昁梫嵟彫尷偺價僢僩悢乮=log2(忋尷-壓尷+1)丄彫悢揰埲壓愗忋偘乯偱丄
俀恑朄宍幃偱晞崋壔偟傑偡丅
- 偦偺懠偺応崌丗僆僋僥僢僩惍楍傪偟側偄帠傪彍偒丄惍楍宍幃偲摨偠晞崋壔傪偟傑偡丅
2.6. 僆乕僾儞宆
僆乕僾儞宆偼丄俙俽俶丏侾偺晞崋壔偁傞偄偼偦偺懠偺曽朄偱晞崋壔偝傟偨屻丄
挿偝偵惂尷偑側偄僆僋僥僢僩楍偺條偵埖傢傟丄挿偝俴乮扨埵偼僆僋僥僢僩乯偲丄
偦傟偵懕偔僆僋僥僢僩楍偲偟偰晞崋壔偝傟傑偡丅
惍楍宍幃偱偼僆僋僥僢僩惍楍偑峴傢傟傑偡丅
3. 宆枅偺晞崋壔
3.1. 榑棟宆(BOOL)
侾價僢僩偺旕惍楍價僢僩僼傿乕儖僪偱晞崋壔偟傑偡丅
TRUE偺抣偼侾偱丄FALSE偺抣偼0偱偡丅
挿偝俴偼巊偄傑偣傫丅
3.2. 惍悢宆(INTEGER)
埲壓偺惂栺傪峫椂偟丄惍悢偺忋尷壓尷傪寛掕偟傑偡丅
惍悢宆偺晞崋壔偼埲壓偺捠傝偱偡丅
嘆傕偟丄奼挘儅乕僋偑巜掕偝傟傞側傜丄僾儕傾儞僽儖偲偟偰侾價僢僩偺旕惍楍價僢僩僼傿乕儖僪傪晞崋壔偟傑偡丅
抣偑丄尦乆掕媊偝傟偨斖埻偱偁傟偽旕惍楍價僢僩僼傿乕儖僪偺抣偼0偱丄斖埻奜乮奼挘偝傟偨抣乯偱偁傟偽抣偼侾偱偡丅
抣偑0偺応崌偼嘇傊丄奼挘偟偨抣偺応崌偼嘍傊恑傒傑偡丅
側偍丄惍悢宆偺晞崋壔偱偼惍悢偺忋尷偲壓尷偩偗傪峫偊偰偄傞偨傔丄
奼挘偟偨抣偱偁偭偰傕尦偺忋尷偲壓尷偺斖埻撪偵偁傟偽丄奼挘偝傟偰偄側偄抣偲埖偄傑偡丅
嘇傕偟丄惂栺忦審偑抣傪侾偮偵惂尷偡傞側傜丄抣傪晞崋壔偣偢乮亖挿偝俴傗抣倁偼徣棯乯丄庤弴傪廔椆偟傑偡丅
嘊傕偟丄惂栺忦審偑抣偺斖埻傪惂尷偡傞側傜丄桳尷斖埻偺惍悢偲偟偰晞崋壔偟丄庤弴傪廔椆偟傑偡丅
嘋傕偟丄惂栺忦審偑抣偺壓尷傪帵偡側傜丄晹暘惂尷惍悢偲偟偰晞崋壔偟丄庤弴傪廔椆偟傑偡丅
嘍抣傪惂尷側偟偺惍悢偱晞崋壔偟丄庤弴傪廔椆偟傑偡丅
|
奼挘儅乕僋側偟 |
奼挘儅乕僋桳傝 |
| 奼挘側偟偺抣斖埻 |
奼挘偟偨抣斖埻 |
| 抣偼屌掕抣 |
晞崋壔偟側偄 |
![[0]](per05.png) |
![[1][惂尷側偟惍悢]](per06.png) |
| 抣偼桳尷斖埻 |
![[桳尷斖埻惍悢]](per07.png) |
![[0][桳尷斖埻惍悢]](per08.png) |
| 抣偺壓尷偁傝 |
![[晹暘惂尷惍悢]](per09.png) |
![[0][晹暘惂尷惍悢]](per10.png) |
| 抣偺惂尷側偟 |
![[惂尷側偟惍悢]](per11.png) |
![[0][惂尷側偟惍悢]](per12.png) |
3.3.楍嫇宆(ENUMERATED)
楍嫇宆偺晞崋壔偼埲壓偺捠傝偱偡丅
嘆傕偟奼挘儅乕僋偑巜掕偝傟傞側傜丄僾儕傾儞僽儖偲偟偰丄侾價僢僩偺旕惍楍價僢僩僼傿乕儖僪傪晞崋壔偟傑偡丅
抣偑丄嵟弶偵掕媊偝傟偨斖埻偱偁傟偽旕惍楍價僢僩僼傿乕儖僪偺抣偼0偱丄
斖埻奜乮奼挘偝傟偨抣乯偱偁傟偽抣偼侾偱偡丅 抣偑0偺応崌偼嘇傊丄奼挘偟偨抣偺応崌偼嘊傊恑傒傑偡丅
嘇楍嫇宆偺梫慺傪梫慺抣偺弴斣偵暲傋丄侽偐傜弴偵斣崋傪怳傝捈偟傑偡
乮尦偺梫慺抣偑旘傃旘傃偱傕娫傪媗傔偰斣崋傪怳傝側捈偟傑偡乯丅
斣崋傪丄嵟彫抣偼侽偱嵟戝抣偼嵟屻偺梫慺偺斣崋偺桳尷斖埻偺惍悢偲偟偰晞崋壔偟丄庤弴傪廔椆偟傑偡丅
嘊旕奼挘偺梫慺傪彍偒丄楍嫇宆偺梫慺傪梫慺抣偺弴斣偵暲傋丄侽偐傜弴偵斣崋傪怳傝捈偟傑偡丅
偙偺帪丄傛傝怴偟偄梫慺偼傛傝屻偵暲傋傑偡丅斣崋傪丄 捠忢彫偝偄旕晧惍悢
偲偟偰晞崋壔偟丄庤弴傪廔椆偟傑偡丅
| 奼挘儅乕僋側偟 |
奼挘儅乕僋桳傝 |
| 奼挘側偟偺抣斖埻 |
奼挘偟偨抣斖埻 |
|
|
![[1][捠忢彫偝偄旕晧惍悢]](per13.png) |
3.4. 幚悢宆(REAL宆)
幚悢宆偺晞崋壔偼CER/DER偲傎傏摨偠偱偡丅
CER/DER偵偍偗傞幚悢偺晞崋壔抣偑len僆僋僥僢僩偲偟傑偡丅
挿偝俴=len傪傑偢晞崋壔偟丄懕偄偰CER/DER晞崋壔偺抣乮僞僌傗挿偝傪彍偔乯傪晞崋壔偟傑偡丅
屻幰偼丄惍楍宍幃偱偁傟偽僆僋僥僢僩惍楍偟丄旕惍楍宍幃偱偁傟偽惍楍偟傑偣傫丅
![[L][CER/DER偲摨偠晞崋壔]](per14.png)
3.5. 價僢僩楍宆(BIT STRING)
埲壓偺惂栺傪峫椂偟傑偡丅
價僢僩楍宆偺晞崋壔偼埲壓偺捠傝偱偡丅
嘆傕偟丄柤慜偮偒價僢僩楍宆偱偁傟偽丄價僢僩楍偺屻傠偺晄梫側侽偼嶍彍偝傟傑偡丅
嘇傕偟僒僀僘惂栺忦審偑偁傞側傜丄僒僀僘惂栺忦審傪枮偨偡斖埻偱丄挿偝偑嵟彫偵側傞傛偆偵丄
價僢僩楍偺嵟屻偵侽傪捛壛偟偨傝丄價僢僩傪嶍彍偟偨傝偟傑偡丅
嘊傕偟丄僒僀僘惂尷偵奼挘儅乕僋偑偁傞側傜丄僾儕傾儞僽儖偲偟偰丄
侾價僢僩偺旕惍楍價僢僩僼傿乕儖僪傪晞崋壔偟傑偡丅
抣偑丄嵟弶偵掕媊偝傟偨斖埻偱偁傟偽旕惍楍價僢僩僼傿乕儖僪偺抣偼0偱丄
斖埻奜乮奼挘偝傟偨抣乯偱偁傟偽抣偼侾偱偡丅 抣偑0偺応崌偼嘋傊丄奼挘偟偨抣偺応崌偼嘑傊恑傒傑偡丅
嘋傕偟丄僒僀僘偺忋尷偑僛儘側傜丄價僢僩偼懚嵼偟側偄偺偱丄
晞崋壔偣偢乮亖挿偝俴傗抣倁偼徣棯乯丄庤弴傪廔椆偟傑偡丅
嘍傕偟丄僒僀僘偑屌掕挿乮僒僀僘壓尷亖僒僀僘忋尷乯偱侾俇價僢僩埲壓側傜丄
價僢僩楍偼挿偝側偟偱丄巜掕偝傟偨挿偝偱晞崋壔偟丄庤弴傪廔椆偟傑偡丅僆僋僥僢僩惍楍傪偟傑偣傫丅
嘐傕偟丄僒僀僘偑屌掕挿乮僒僀僘壓尷亖僒僀僘忋尷乯偱侾俈價僢僩埲忋俇俆俆俁俇價僢僩埲壓側傜丄
價僢僩楍偼挿偝側偟偱丄巜掕偝傟偨挿偝偱晞崋壔偟丄庤弴傪廔椆偟傑偡丅
惍楍宍幃偺応崌偼僆僋僥僢僩惍楍傪偟傑偡丅
嘑價僢僩楍偺挿偝俴價僢僩傪丄惂尷惍悢乮僒僀僘忋尷偑桳尷偺応崌乯丄
傑偨偼丄晹暘惂尷惍悢乮奼挘偝傟偨抣傗僒僀僘忋尷偑柍尷偺応崌乯偱晞崋壔偟傑偡丅
懕偄偰挿偝俴價僢僩偺價僢僩楍傪晞崋壔偟傑偡丅
|
挿偝偵奼挘儅乕僋側偟 |
挿偝偵奼挘儅乕僋桳傝 |
| 奼挘側偟偺抣斖埻 |
奼挘偟偨抣斖埻 |
| 挿偝侽 |
晞崋壔偟側偄 |
|
![[1][L]](per15.png) |
| 屌掕挿(65536價僢僩埲壓) |
![[價僢僩楍]](per16.png) |
![[0][價僢僩楍]](per17.png) |
![[1][L][價僢僩楍]](per18.png) |
| 偦偺懠 |
![[L][價僢僩楍]](per19.png) |
![[0][L][價僢僩楍]](per20.png) |
3.6. 僆僋僥僢僩楍宆(OCTET STRING)
埲壓偺惂栺傪峫椂偟傑偡丅
僆僋僥僢僩楍宆偺晞崋壔偼埲壓偺捠傝偱偡乮扨埵偑堘偆埲奜偼丄價僢僩楍宆偲摨條偱偡乯丅
嘆傕偟僒僀僘惂尷偑偁傝丄奼挘儅乕僋偑懚嵼偡傞側傜丄僾儕傾儞僽儖偲偟偰丄
侾價僢僩偺旕惍楍價僢僩僼傿乕儖僪傪晞崋壔偟傑偡丅
抣偑丄嵟弶偵掕媊偝傟偨斖埻偱偁傟偽旕惍楍價僢僩僼傿乕儖僪偺抣偼0偱丄
斖埻奜乮奼挘偝傟偨抣乯偱偁傟偽抣偼侾偱偡丅
抣偑0偺応崌偼嘇傊丄奼挘偟偨抣偺応崌偼嘋傊恑傒傑偡丅
嘇傕偟丄僒僀僘偺忋尷偑僛儘側傜丄僆僋僥僢僩偼懚嵼偟側偄偺偱丄
晞崋壔偣偢乮亖挿偝俴傗抣倁偼徣棯乯丄庤弴傪廔椆偟傑偡丅
嘊傕偟丄僒僀僘偑屌掕挿乮僒僀僘壓尷亖僒僀僘忋尷乯偱俀僆僋僥僢僩埲壓側傜丄
僆僋僥僢僩楍偼挿偝側偟偱丄巜掕偝傟偨挿偝偱晞崋壔偟丄庤弴傪廔椆偟傑偡丅
僆僋僥僢僩惍楍傪偟傑偣傫丅
嘐傕偟丄僒僀僘偑屌掕挿乮僒僀僘壓尷亖僒僀僘忋尷乯偱俀僆僋僥僢僩埲忋俇俆俆俁俇僆僋僥僢僩埲壓側傜丄
僆僋僥僢僩楍偼挿偝側偟偱丄巜掕偝傟偨挿偝偱晞崋壔偟丄庤弴傪廔椆偟傑偡丅
惍楍宍幃偺応崌偼僆僋僥僢僩惍楍傪偟傑偡丅
嘋僆僋僥僢僩楍偺挿偝俴僆僋僥僢僩傪丄惂尷惍悢乮僒僀僘忋尷偑桳尷偺応崌乯丄傑偨偼丄
晹暘惂尷惍悢乮僒僀僘忋尷偑柍尷偺応崌乯偱晞崋壔偟傑偡丅
懕偄偰挿偝俴僆僋僥僢僩偺僆僋僥僢僩楍傪晞崋壔偟傑偡丅
3.7. 僰儖宆(NULL)
晞崋壔偟傑偣傫丅
僰儖宆偼幚幙揑偵偼丄慖戰宆偱偺慖戰巿偑側偄応崌傗丄廤崌宆偲弴彉楍宆偺僆僾僔儑儞梫慺偺丄寠杽傔偱巊傢傟傑偡丅
僾儕傾儞僽儖偑偁傞偺偱慖戰宆偱偺僰儖偺慖戰傗丄僆僾僔儑儞梫慺偼丄僰儖偺僆僋僥僢僩昞尰側偟偱幚峴偱偒傑偡丅
3.8. 弴彉楍宆(SEQUENCE)
嘆傕偟弴彉楍宆偵奼挘儅乕僋偑懚嵼偡傞側傜丄僾儕傾儞僽儖偲偟偰丄侾價僢僩偺旕惍楍價僢僩僼傿乕儖僪傪晞崋壔偟傑偡丅 捛壛偝傟偨梫慺偑懚嵼偟側偗傟偽旕惍楍價僢僩僼傿乕儖僪偺抣偼0偱丄捛壛偝傟偨梫慺偑懚嵼偡傟偽抣偼侾偱偡丅
嘇傕偟丄奼挘梫慺傪彍偒丄弴彉楍宆偺拞偵OPTIONAL偐DEFAULT偲巜掕偝傟偨梫慺偑値屄懚嵼偡傞側傜丄
僾儕傾儞僽儖偲偟偰丄値價僢僩偺價僢僩僼傿乕儖僪傪晞崋壔偟傑偡丅
僆僋僥僢僩惍楍傪偟傑偣傫丅
値價僢僩偺奺價僢僩偼丄OPTIONAL偐DEFAULT偺梫慺偑懚嵼偡傞偐斲偐傪帵偟傑偡丅
懚嵼偡傟偽侾偱丄懚嵼偟側偗傟偽侽偱晞崋壔偟傑偡丅
愭摢價僢僩偑弴彉楍宆偺拞偺嵟弶偺OPTIONAL偐DEFAULT偺梫慺偺懚嵼傪帵偟傑偡丅
側偍丄値偑俇俆俆俁俈埲忋偺応崌偼晞崋壔曽朄偑彮偟曄傢傝傑偡偑丄偙偙偱偼徣棯偟傑偡丅
嘊僾儕傾儞僽儖偵懕偄偰弴彉楍宆偺丄奼挘梫慺傪彍偔奺梫慺傪丄弴斣偵偦傟偧傟偺宆偺晞崋壔曽朄偱晞崋壔偟傑偡丅
OPTIONAL偐DEFAULT偺梫慺偱懚嵼偟側偄傕偺偼晞崋壔偟傑偣傫丅
嘋惓婯壔宍幃偱丄DEFAULT偲巜掕偝傟偨梫慺偼抣偑僨僼僅儖僩抣偵堦抳偡傞応崌偵偼丄忢偵晞崋壔偟傑偣傫丅
婎杮宍幃偱丄DEFAULT偲巜掕偝傟偨梫慺偼扨弮宆偱抣偑僨僼僅儖僩抣偵堦抳偡傞応崌偵偼丄忢偵晞崋壔偟傑偣傫丅
峔憿宆偺応崌偼丄晞崋壔偡傞偐偳偆偐偼僐乕僟偺擟堄偱偡丅
嘍奼挘梫慺偑懚嵼偟側偄応崌偼丄偙偙偱晞崋壔偼廔椆偟傑偡丅
嘐奼挘梫慺偺悢値傪丄乽捠忢彫偝偄旕晧惍悢乿偱晞崋壔偟傑偡丅
乮傕偟偐偟偨傜丄n偱側偔n-1傪晞崋壔偡傞偐傕偟傟側偄丒丒丒乯
嘑懕偄偰丄値價僢僩偺價僢僩僼傿乕儖僪傪晞崋壔偟傑偡丅
値價僢僩偺奺價僢僩偼奼挘梫慺偑懚嵼偡傞偐斲偐傪帵偟傑偡丅
懚嵼偡傟偽侾丄懚嵼偟側偗傟偽侽偱偡丅
側偍丄俀廳尞妵屖偱埻傑傟偨堦孮偺梫慺偼丄堦孮偺梫慺慡懱偑侾偮偺SEQUENCE梫慺偱偁傞偐偺條偵埖偄傑偡丅
嘒懕偄偰丄懚嵼偡傞奼挘梫慺傪弴斣偵弴斣偵晞崋壔偟傑偡丅
晞崋壔偼丄偦傟偧傟偺宆偺晞崋壔曽朄偱晞崋壔偟偨傕偺傪丄僆乕僾儞宆偺抣偲偟偰晞崋壔偟傑偡丅
| 奼挘儅乕僋 |
奼挘 |
|
| 側偟 |
亅 |
![[梫慺偺桳柍][梫慺][梫慺]乧[梫慺]](per21.png) |
| 偁傝 |
側偟 |
![[0][梫慺偺桳柍][梫慺][梫慺]乧[梫慺]](per22.png) |
| 偁傝 |
偁傝 |
![[1][梫慺偺桳柍][梫慺][梫慺]乧[梫慺][奼挘梫慺悢][梫慺偺桳柍][梫慺][梫慺]乧[梫慺]](per23.png) |
3.9. 扨堦弴彉楍宆(SEQUENCE OF)
埲壓偺惂栺傪峫椂偟傑偡丅
嘆傕偟丄僒僀僘惂尷偑奼挘壜擻偱偁傟偽丄僾儕傾儞僽儖偲偟偰丄侾價僢僩偺旕惍楍價僢僩僼傿乕儖僪傪晞崋壔偟傑偡丅
僒僀僘偑尦乆巜掕偝傟偨斖埻撪偱偁傟偽旕惍楍價僢僩僼傿乕儖僪偺抣偼0偱丄斖埻奜偱偁傟偽抣偼侾偱偡丅
抣偑0偺応崌偼嘇傊恑傒傑偡丅 奼挘偟偨抣偺応崌偼梫慺悢値傪晹暘惂尷惍悢偱晞崋壔偟傑偡丅
懕偄偰値屄偺梫慺傪晞崋壔偟丄庤弴傪廔椆偟傑偡丅
嘇傕偟丄僒僀僘惂尷偱梫慺悢値偑屌掕挿乮僒僀僘壓尷亖僒僀僘忋尷乯偱俇俆俆俁俇屄埲壓側傜丄
梫慺悢値偼晞崋壔偣偢丄値屄悢偺梫慺傪晞崋壔偟丄庤弴傪廔椆偟傑偡丅
嘊梫慺悢値傪丄惂尷惍悢乮僒僀僘忋尷偑桳尷偺応崌乯傑偨偼晹暘惂尷惍悢乮僒僀僘忋尷偑柍尷偺応崌乯偱晞崋壔偟傑偡丅
懕偄偰値屄悢偺梫慺傪晞崋壔偟丄庤弴傪廔椆偟傑偡丅
3.10. 廤崌宆(SET)
廤崌宆傪晞崋壔偡傞応崌丄梫慺偺弴彉傪惓婯壔偟丄SEQUENCE宆偲摨偠晞崋壔傪偟傑偡丅
[奼挘偝傟偰偄側偄梫慺偼丄僞僌弴偵暲傋傑偡丅 僞僌偺弴彉偲偼斈梡丄墳梡丄暥柆摿掕丄巹梡偺僋儔僗弴偱丄
摨偠僋儔僗偱偼僞僌偺悢帤偑彫偝偄傕偺偑愭丄戝偒偄傕偺偑屻偵側傝傑偡丅
梫慺偑僞僌側偟偺CHOICE宆偺応崌丄CHOICE宆梫慺偺僥僉僗僩偱嵟弶偵婰弎偝傟偰偄傞梫慺偺僞僌抣傪帩偮偲峫偊傑偡丅
奼挘梫慺偼俙俽俶丏侾巇條偺僥僉僗僩偺婰弎弴彉偱暲傋傑偡丅
3.11. 扨堦廤崌宆(SET OF)
埲壓偺惂栺傪峫椂偟傑偡丅
- 僒僀僘丗挿偝偺惂尷
- 惂栺忦審偺慻崌偣丗廤崌榓丄廤崌愊丄攔懠丄彍奜側偳偺墘嶼偱惂栺忦審傪慻傒崌傢偣傞丅
- 奼挘惂栺丗彨棃偺奼挘壜擻惈偺巜掕
惓婯壔宍幃偱偼丄梫慺偼忋徃弴偱暲傋傜傟傑偡丅斾妑偼奺梫慺傪價僢僩楍偲偟偰斾妑偟傑偡丅
晞崋壔偼SEQUENCE OF宆偲摨條偱偡丅
3.12. 慖戰宆(CHOICE)
嘆傕偟丄慖戰宆偵奼挘儅乕僋偑懚嵼偡傞側傜丄僾儕傾儞僽儖偲偟偰丄
侾價僢僩偺旕惍楍價僢僩僼傿乕儖僪傪晞崋壔偟傑偡丅
僒僀僘偑尦乆巜掕偝傟偨斖埻撪偱偁傟偽旕惍楍價僢僩僼傿乕儖僪偺抣偼0偱丄斖埻奜偱偁傟偼侾偱偡丅
嘇慖戰宆偵暋悢偺慖戰巿偑偁傞応崌丄
偳偺梫慺偑慖戰偝傟偨偐傪帵偡僀儞僨僢僋僗抣乮嵟彫抣侽丄嵟戝抣偼慖戰巿偺悢亅侾乯傪晞崋壔偟傑偡丅
奼挘偝傟偰偄側偄梫慺偺僀儞僨僢僋僗抣偼丄梫慺傪僞僌弴偵暲傋丄愭摢傪侽偲偟偰丄
弴斣偵斣崋傪怳偭偨傕偺偱偡丅
僞僌偺弴彉偲偼斈梡丄墳梡丄暥柆摿掕丄巹梡偺僋儔僗弴偱丄
摨偠僋儔僗偱偼僞僌偺悢帤偑彫偝偄傕偺偑愭丄戝偒偄傕偺偑屻偵側傝傑偡丅
梫慺偑僞僌側偟偺慖戰宆偺応崌丄慖戰宆梫慺偺僥僉僗僩偱嵟弶偵婰弎偝傟偰偄傞梫慺偺僞僌抣傪帩偮偲峫偊傑偡丅
奼挘梫慺偺僀儞僨僢僋僗抣偼俙俽俶丏侾巇條偺僥僉僗僩偺婰弎弴彉偱暲傋丄愭摢傪侽偲偟偰丄弴斣偵斣崋傪怳偭偨傕偺偱偡丅
僀儞僨僢僋僗抣偺晞崋壔曽朄偼丄奼挘偝傟偰偄側偄梫慺偺応崌惍悢宆偱丄
奼挘梫慺偺応崌偼丄捠忢彫偝偄旕晧惍悢偱晞崋壔偟傑偡丅慖戰宆偺慖戰巿偑侾偮偟偐側偗傟偽丄
僀儞僨僢僋僗抣偺晞崋壔偼偟傑偣傫丅
嘊嵟屻偵梫慺傪晞崋壔偟傑偡丅
奼挘偝傟偰偄側偄梫慺偼偦偺傑傑晞崋壔偟丄奼挘梫慺偼丄僆乕僾儞宆偺抣偲偟偰晞崋壔偟傑偡丅
|
奼挘儅乕僋側偟 |
奼挘儅乕僋桳傝 |
| 奼挘側偟偺梫慺 |
奼挘偟偨梫慺 |
| 慖戰巿偑侾屄 |
![[梫慺]](per30.png) |
![[0][梫慺]](per31.png) |
(偁傝偊側偄丠) |
| 偦偺懠 |
![[僀儞僨僢僋僗][梫慺]](per32.png) |
![[0][僀儞僨僢僋僗][梫慺]](per33.png) |
![[1][僀儞僨僢僋僗][梫慺]](per34.png) |
3.13. 僆僽僕僃僋僩幆暿巕宆(OBJECT IDENTIFIER)
晞崋壔屻偺僆僋僥僢僩悢俴偵懕偄偰丄抣傪俛俤俼偺抣偲摨偠曽朄偱晞崋壔偟傑偡丅
3.14. 惂尷暥帤楍宆(RESTRICTED CHARACTER STRING)
埲壓偺惂栺傪峫椂偟傑偡丅
- 嫋梕傾儖僼傽儀僢僩(from)丗
巊梡偱偒傞傾儖僼傽儀僢僩傪惂尷
椺丗Morse ::= PrintableString (FROM ("."|"-"|" "))
椺丗IDCardNumber ::=NumericString (FROM ("0".."9"))
椺丗PushButtonDialSequence ::=IA5String (FROM ("0".."9"|"*"|"#"))
- 僒僀僘丗挿偝偺惂尷
- 曪娷丗婛懚偺惂栺傪慻傒崌傢偣偨惂栺
椺: LongWeekEnd ::= Day (WeekEnd|monday)
- 惂栺忦審偺慻崌偣丗廤崌榓丄廤崌愊丄攔懠丄彍奜側偳偺墘嶼偱惂栺忦審傪慻傒崌傢偣傞丅
- SIZE偺奼挘惂栺丗彨棃偺奼挘壜擻惈偺巜掕
嘆婎杮揑偵暥帤悢俴偵懕偄偰暥帤楍傪晞崋壔偟傑偡丅
嘇奺暥帤偼嵟彮價僢僩悢偱晞崋壔偟傑偡丅
旕惍楍宆偺応崌丄FROM惂栺偺揔梡偵傛偭偰巊梡壜擻側暥帤悢偑俶偱偁傟偽丄
log2(N)價僢僩乮彫悢揰埲壓愗忋偘乯偱晞崋壔偟傑偡丅
惍楍宆偺応崌丄log2(N)傛傝戝偒偄丄俀偺椵忔偵側傞價僢僩挿
乮偮傑傝丄侾價僢僩丄俀價僢僩丄係價僢僩丄俉價僢僩丄侾俇價僢僩丒丒丒乯偱晞崋壔偟傑偡丅
奺暥帤偺懳墳偡傞抣偼丄奺暥帤偺抣傪彫偝偄弴偵暲傋偰丄侽傜偐弴偵抣傪怳傝側偍偟偨傕偺偱偡丅
扐偟丄FROM惂栺偑奼挘壜擻偱偁傟偽丄FROM惂栺偼側偄傕偺偲傒側偟傑偡
乮尦偲側傞宆偺慡偰偺暥帤偑巊偊傞偲峫偊傑偡乯丅
嘊傕偟僒僀僘惂尷偑偁傝丄奼挘儅乕僋偑懚嵼偡傞側傜丄僾儕傾儞僽儖偲偟偰丄
侾價僢僩偺旕惍楍價僢僩僼傿乕儖僪傪晞崋壔偟傑偡丅
抣偑丄嵟弶偵掕媊偝傟偨斖埻偱偁傟偽旕惍楍價僢僩僼傿乕儖僪偺抣偼0偱丄
斖埻奜乮奼挘偝傟偨抣乯偱偁傟偽抣偼侾偱偡丅
抣偑0偺応崌偼嘋傊丄奼挘偟偨抣偺応崌偼嘐傊恑傒傑偡丅
嘋傕偟丄僒僀僘偑屌掕挿乮僒僀僘壓尷亖僒僀僘忋尷乯偱丄
晞崋壔偟偨暥帤楍偑俀僆僋僥僢僩埲壓側傜丄
暥帤楍偼挿偝側偟偱丄巜掕偝傟偨挿偝偱晞崋壔偟丄庤弴傪廔椆偟傑偡丅
僆僋僥僢僩惍楍傪偟傑偣傫丅
嘍傕偟丄僒僀僘偑屌掕挿乮僒僀僘壓尷亖僒僀僘忋尷乯偱晞崋壔偟偨暥帤楍偑俀僆僋僥僢僩埲忋俇俆俆俁俇暥帤埲壓側傜丄
價僢僩楍偼挿偝側偟偱丄巜掕偝傟偨挿偝偱晞崋壔偟丄庤弴傪廔椆偟傑偡丅
惍楍宍幃偺応崌偼僆僋僥僢僩惍楍傪偟傑偡丅
嘐暥帤楍偺挿偝俴暥帤傪丄
惂尷惍悢乮僒僀僘忋尷偑桳尷偺応崌乯傑偨偼晹暘惂尷惍悢乮僒僀僘忋尷偑柍尷偺応崌乯偱晞崋壔偟傑偡丅
懕偄偰挿偝俴暥帤偺暥帤楍傪晞崋壔偟傑偡丅
婰弎撪梕偵偮偄偰堦愗曐忈偟傑偣傫丅儕儞僋偼帺桼偵峴偭偰偐傑偄傑偣傫丅
Since 2006/6/19, Final update 2006/7/8, Presented by Ishida So
![[1][n]](per24.png)
![[梫慺]乧[梫慺]](per25.png)
![[0][梫慺]乧[梫慺]](per26.png)
![[1][n][梫慺]乧[梫慺]](per29.png)
![[n][梫慺]乧[梫慺]](per27.png)
![[0][n][梫慺]乧[梫慺]](per28.png)